In this article, David Standingford, Lead Technologist, provides his view on how data visualisation is helping CFD engineers see the bigger picture more easily with technology found in computer science.
We are getting better and better at producing vast amounts of raw data in support of engineering analysis. Computational fluid dynamics (CFD) in particular has seen spectacular increases in the production of simulation data – increasingly unsteady (time-accurate) and scale resolving.
Much of this is enabled by the mega-trend of exponentially decreasing cost in computational hardware for processing and data storage. Not that many years ago, a steady-state CFD simulation with a million cells in the computational mesh would have been regarded as the province of high-end industrial users only, and certainly out of scope for routine design space exploration. Nowadays, simulations with several million cells can be run on desktop workstations and high end users are starting to use simulations with circa 1 billion cells. The Gordon Bell Prize – for sustained and scalable computational performance is now recording entries with over 1 petaflops in double precision arithmetic, and we will soon likely see 10 petaflops for CFD. The humble million-cell calculation – if run on cloud commodity hardware – would cost about £1.
So what exactly is being done with all that data? Clearly not all of it is kept. It should be noted that much of the processing power used during a simulation is used to create intermediate results on the iterative journey towards a usable answer. For example, the £1 simulation above might sustain a modern CPU-based computer at circa 100 GFLOPS (100 billion floating point operations per second) for an hour (3600 seconds). The output would be a data file with about 1GB of data (including the mesh for post-processing) so the ratio of floating point operations per output byte is of the order of a million to 1. For unsteady simulations, this ratio might decrease somewhat, but probably not less than about 1000 to 1.
Even if we are only directly interested in one in a million of the floating point data elements generated during a simulation, it is clear that a 1 petaflops machine is going to produce an unmanageable amount of data. Such a simulation would, each hour, produce 10 TB of data. How does this translate into engineering insight?
Generally it doesn’t. Many very impressive videos have been produced by pro-processing large unsteady simulation datasets. The tools for rendering and managing the visualisation data have actually been keeping pace reasonably well with the rate of production – fuelled by the same global megatrends. What has had rather less attention is the visual artefacts generated by these tools. Standard idioms for flow visualisation (streamlines, contours, pressure plots and even the more recent line-integral convolution) have been relatively stable over many years and accepted as the only way to look at flow field data.
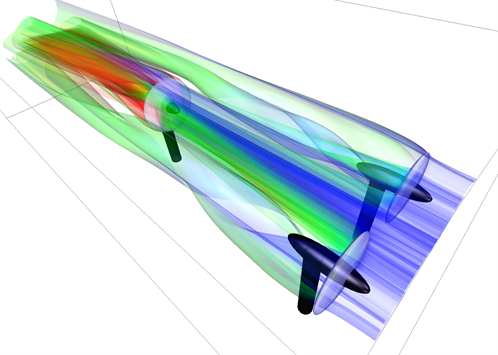
This is where the exciting area of information-driven visualisation research steps in. Computer algorithms to help decide how to look at a given flow use flow field features and patterns in the flow itself. This has already led to the development of automatic streamline and stream-surface placement in unsteady flow simulations – resulting in the novel forms of visualisation shown below.
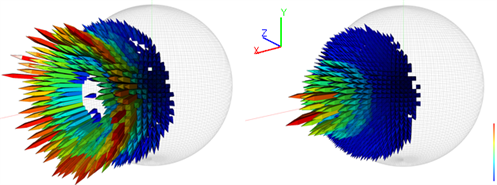
Pioneering work by Robert S. Laramee, Associate Professor, Data Visualisation at the University of Swansea is helping CFD engineers see the bigger picture more easily with technology founded in computer science. According to Laramee, the next challenges on the horizon are multi-field visualization and four-dimensional flow visualization.
To download the full paper Visualization of Flow Past a Marine Turbine: The Information-Assisted Search for Sustainable Energy by Zhenmin Peng, Zhao Geng, Michael Nicholas, Robert S. Laramee, Nick Croft, Rami Malki, Ian Masters, Chuck Hansen, click below.