There are three vital decisions that fundamentally influence optimal architecture for analytics and Internet of Things (IoT). Pursuing these decisions will link business needs with technical implementations, increasing the likelihood of success.
To date, many IoT architectures have been driven by expedience and technology rather than a careful understanding of the end goals. While this has allowed for rapid iteration, it’s also a recipe for disaster. As the amount of IoT-generated data rapidly increases, selecting the optimal architecture for edge analytics becomes a critical operational and technical challenge—get it wrong and it could be the end of your business.
It’s important to learn from lessons of the past. Enterprises must create a clear picture of their desired outcomes and connect technologists with business leaders. The two must come together to ensure that use cases drive analytics.
Now is the time to make these decisions. By the end of 2019, digital transformation spending will reach $1.7 trillion worldwide, a 42% increase from 20171. Moreover, 94% of enterprise decision-makers said analytics are important or critical to their digital transformation efforts2. It’s fair to say that without analytics, digital transformation is unlikely to be successful.
Here’s the conundrum: many analytics undertakings have a poor track record of delivering value to the business. Often, this is because the enterprise failed to identify, upfront, a clear set of desired business outcomes. Collecting data for the future became the objective. Figuring out how to extract insight from the data would come later… until it hasn’t.
While any full implementation of IoT analytics will require hundreds of decisions, there are three vital decisions—about time, volume and visibility—that fundamentally influence the optimal architecture for your business. Pursuing these decisions will link business needs with technical implementations, minimising wasted effort and increasing the likelihood of success.
Decision #1 – Time sensitivity: how quickly must data be analysed?
Fractions of a second can make an enormous difference in the choice and cost of a technology implementation. Real-time analytics doesn’t mean the same to everyone. For example, some control decisions in drones and autonomous vehicles can require sub-microsecond response times. Industrial control systems might need to respond in tens of microseconds to avoid damage and ensure safety. Whereas other devices, such as climate and temperature sensors, might only need to collect data once every few minutes3.
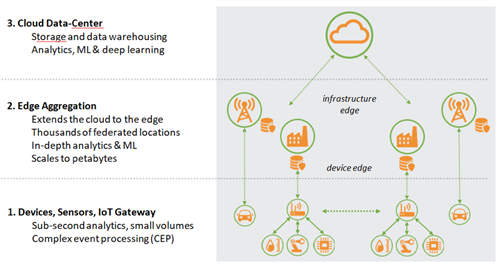
Achieving sub-second response times requires that edge analytics be performed close to the source of the data, including within the connected devices themselves or within a local gateway device. The advent of high-speed 5G wireless networks and infrastructure edge data centres will also allow response times measured in milliseconds, so some of this processing can be offloaded to the infrastructure. Complex event processing (CEP) software can help process inbound streams of data in the device edge as well as at the infrastructure edge, depending on the use case. In order to properly architect an analytics system, designers must understand the use case and the level of responsiveness required.
Decision #2 – Data transfer: can data volumes be reduced? Where should the data go?
For analytics that can tolerate access and analysis within a few seconds, edge processing can and should move further away from the sources of data. How far away data can be transferred, or moved, is determined primarily by the volume of data and the bandwidth which is available.
Since IoT devices and gateways are optimised for low power and minimal cost, they often have significant constraints on processing and how much data they can store on board—sometimes only hours of data at best. In addition to determining how quickly the data must be analysed, a decision must also be made on what data will be retained, after initial processing, by transferring the data elsewhere for additional analysis and storage.
The volume of data generated by different types of IoT devices can vary greatly. In aggregate, an estimated 30 billion connected IoT devices will generate 600 ZB of new data every year. On average that’s more than 50 GB of data per device, every day. For perspective, a single aircraft with modern engines will generate 2-5 TB of data every day. An autonomous car can generate up to 3 TB every hour.
There are strategies that can be employed to manage large volumes of data for analytics:
Should you reduce the data?
It is critical to understand what data must be retained after initial processing so you know what you can get rid of. In some cases, it is obvious what to throw out, as some data doesn’t provide subsequent value. For example, if time-stamped data is sent continuously from an engine to relay the message of “working properly”, this data can be deleted shortly after it is processed. Reduction would require saving only the data when a questionable operation, communication fault or failure is detected.
Other times, saving data for additional analysis is critical. What about atmospheric and telemetry data that provides insight when analysed at a later time? Is it sufficient to only send a daily summary of the data without any of the underlying detail? Predictive maintenance, forecasting, digital twin modeling and machine learning algorithms often benefit from having as large a dataset as possible—which means holding on to a large percentage of the data.
Should the data be transferred? If so, where?
Once it is agreed upon as to which data must be kept, then it’s straightforward to estimate how long it takes to ship data before it’s available for analysis. Traditionally, data is shipped to a centralised location such as a private data warehouse or a cloud provider’s storage. With escalating data volumes, this becomes problematic. Google provides estimates on how long it takes to transfer data to its own cloud platform. For example, 10 TB of data would take approximately 30 hours when 1 Gbps of network bandwidth is available. It would take 12 days to ship the same 10 TB of data across a 10 Mbps Internet connection. And this is before any bandwidth limitations, caps and transfer costs are considered.
If you deem this “data blind spot” too large, you must consider an edge architecture to bring the cloud closer to the device. The edge makes it possible to analyse petabytes of data aggregated from millions of devices, without having to wait to transfer to a central cloud location. Analytics can be distributed at the device edge – by deploying servers in very close proximity to IoT gateways including locations such as factories, hospitals, oil rigs, banks and retail stores. Analytics can also be distributed at the infrastructure edge, within same the last-mile network, to thousands of locations such as cell towers and DAS hubs. 5G deployments will help reduce latency for devices that connect to cellular networks, while also increasing bandwidth.
By extending analytics to the edge, newly generated data is available for analysis almost immediately. It can be processed within a matter of seconds and can be retained efficiently and cost-effectively for weeks, months or years. Automated stream processing, machine learning and all forms of in-depth analytical queries can be performed on large volumes of data. Aggregated analytics at the edge seamlessly picks up where millisecond-level CEP performed on smaller data sets within the device/gateway leaves off.
There are some cases related to data privacy and compliance that mandate data reside at the device or infrastructure edge indefinitely. For example, in highly regulated industries such as healthcare and government, it is often prohibited to move data outside of physical locations or across country borders. Data sovereignty and security during transmission will become an increasing challenge for analytics.
Decision #3 – Visibility: Do your edge analytics require federation?
Not all use cases require federation – which is the ability to combine data from many physical locations into one data set for analysis. For example, alerting when a storage facility’s humidity level deviates by more than 5% of the trailing 48-hour average would not require federation. In this case, the ability to analyse data within a single storage facility does not require combining it with data from another.
Other use cases depend on federation. One federated example is to reduce manufacturing defects by analysing process variations across assembly lines in geographically disparate factories. This analysis requires the data from multiple locations to be analysed collectively. Another example is video surveillance where an individual identified using facial recognition must then be correlated across a set of regional databases to quickly determine if the person is a known bad-actor.
There are a variety of approaches to federate analytics in distributed environments. Google has proposed one approach to Federated Learning, where thousands or millions of devices make small, incremental improvements to a machine learning algorithm locally, then ship just the improvements up to a centralised cloud. This methodology makes it possible to train a machine learning model by running training on the devices without shipping all of the data to the cloud.
Another approach is to federate aggregated analytics that reside very close to the devices and gateways, at either the device edge or the infrastructure edge—or both. Rather than shipping data to a central location, data is kept locally and the queries and algorithms are pushed out to meet it at the edge. Distributed queries operate in parallel across the network with predicate and analytical push-down to minimise network traffic and reduce query response times. In this scenario, data might be replicated between edge locations using multi-master synchronisation, but it never has to be shipped back to a centralised cloud. By pushing the queries to the edge, geographically distributed data sources can be analysed through a centralised interface and command— appearing as though all the data were in a single location.
Summary
Suggesting that only three decisions will magically align business owners and technologists together for IoT initiatives is, admittedly, an oversimplification. However, a surprising number of projects don’t first cover these bases. To get your IoT project on track, take the time to determine (1) how quickly data must be analysed, (2) what data must be retained and where should it be transferred based on volumes/privacy, and (3) whether federated visibility is required. These steps will go a long way towards providing a common language between the business users and technical implementation team. In addition, it will help to provide a framework for deeper technical investigations and solutions.